The domain of Natural Language Processing (NLP) provides novel tools for Literary analysis. Analysts use NLP tools to record sentiment, emotional intensity, and word frequencies. Today I use NLP techniques to extract Raskolnikov's speaking (and thinking) quotes from Dostyevsky's Crime and Punishment.
Background
In a prior blog post, I compared the speaker sentiment (positive or negative) and intensity of emotions between the Unabomber and Thoreau. I used their respective manifestos. They wrote their manifestos in the first person and spoke (or thought) every word of text in the document. The fact that neither manifesto includes other speakers drove simple data preparation. I fed each entire document to my NLP models.
Now consider Dostyevsky's Crime and Punishment.

The text includes dozens of characters, each with their own speaking and thinking lines. Since I only want to analyze Raskolnikov, I must extract his text from the book. I filter other characters, narration, and page numbers from the analysis.
I see three ways to extract Raskolnikov's thinking and speaking parts.
- Dive into the book and cut and paste his lines by hand
- Write a series of if/ then heuristics with rules and logic to extract his lines (e.g. if you see the phrase said Raskolnikov, pull the line)
- Train a Machine Learning (ML) model to extract the lines for me
I decide to go with #3 and train a model to do the work for me.
![]()
I use Keras and TensorFlow to train my model.
Label the Training Data
I seed the model with training data. I pull representative lines of text and label them Raskolnikov and Not Raskolnikov with Microsoft EXCEL.
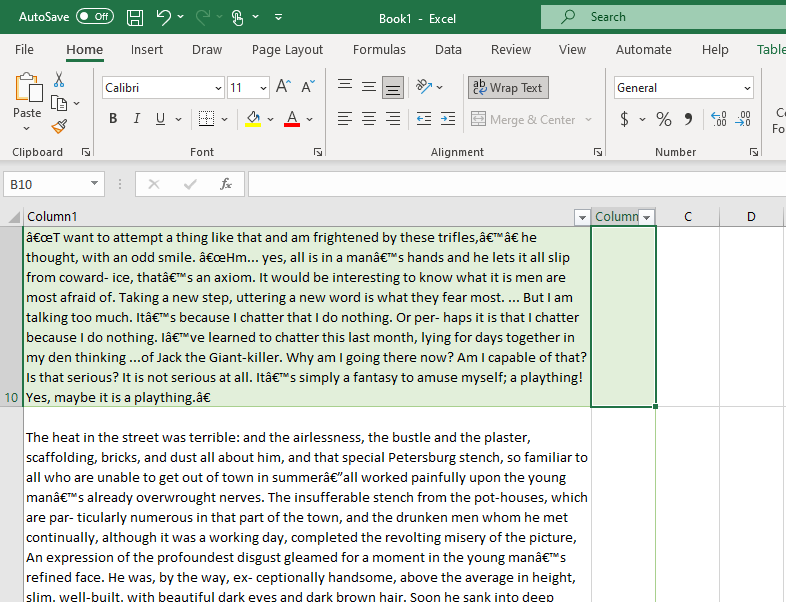
I use my judgment and experience and decide that roughly two hundred and fifty (250) data points should suffice for training.
My EXCEL efforts yield two files: Raskolnikov.txt and Other.txt.
I then use a simple BASH script to put each line into a separate file. The script then moves these files to their appropriate directory. Keras imports the data and labels them based on the name of their parent directory.
i=1
cat Raskolnikov.txt |
while read line;
do echo $line > ./Raskolnikov/R_$i.txt;
((i++));
done
i=1
cat Other.txt |
while read line;
do echo $line > ./Other/O_$i.txt;
((i++));
done
This yields two directories. I then use the Linux mv command to move some of the Raskolnikov and Other labeled files to a testing directory.
I create a parent directory named crime_and_punish, with two sub-directories training and testing each of which contain files for Raskolnikov and Other.
$ tree crime_and_punish
crime_and_punish
├── testing
│ ├── Other (19 Samples)
│ │ ├── O_120.txt
│ │ ├── O_137.txt
│ │ ├── ...
│ │ └── O_138.txt
│ └── Raskolnikov (38 Samples)
│ ├── R_120.txt
│ ├── R_121.txt
│ ├── ...
│ └── R_132.txt
└── training
├── Other (119 Samples)
│ ├── O_100.txt
│ ├── O_99.txt
│ ├── ...
│ └── O_9.txt
└── Raskolnikov (144 Samples)
├── R_100.txt
├── ...
└── R_9.txt
I zip the topmost directory into a zip file for easy portability.
zip -r crime_and_punish.zip crime_and_punish

Train the model
I upload my ZIP file into my Amazon Web Services Sagemaker Notebook through the graphical user interface and then run a code block to extract the labeled dataset.
!unzip crime_and_punish.zip
I import the required Machine Learning libraries.
!pip install keras-nlp
import keras_nlp
import pandas as pd
import tensorflow as tf
from tensorflow import keras
# Use mixed precision for optimal performance
keras.mixed_precision.set_global_policy("mixed_float16")
Keras provides helper functions to import training data into TensorFlow.
BATCH_SIZE = 16
cp_train = tf.keras.utils.text_dataset_from_directory(
"crime_and_punish/training",
batch_size=BATCH_SIZE,
)
cp_test = tf.keras.utils.text_dataset_from_directory(
"crime_and_punish/testing",
batch_size=BATCH_SIZE,
)
The train Dataset includes samples for model training and validation. The test Dataset includes holdout data to surprise our model and simulate real-world interaction.
We inspect the structure of the new tensor object, which wraps each line of text in the tensor encoding.
print(cp_train.unbatch().take(1).get_single_element())
Found 239 files belonging to 2 classes.
Found 32 files belonging to 2 classes.
(<tf.Tensor: shape=(), dtype=string, numpy=b'"Get up, why are you asleep!" she called to him: "It\'s past nine, I have brought you some tea; will you have a cup? I should think you\'re fairly starving?"\r\n'>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
The following commands instruct Keras to train a custom model with a BERT backbone. This Transfer Learning uses the power of a pre-existing NLP model to increase the performance of our custom model.
We first load bert_medium_en_uncased model into our workspace.
classifier = keras_nlp.models.BertClassifier.from_preset(
"bert_medium_en_uncased",
num_classes=2,
)
We then instruct Keras to fine-tune the model based on the training data, cp_train and cp_test:
classifier.fit(
cp_train,
validation_data=cp_test,
epochs=1,
)
Sagemaker outputs the training results:
1/15 [=>............................] - ETA: 30:57 - loss: 0.6997 - sparse_categorical_accuracy: 0.5000
2/15 [===>..........................] - ETA: 10:03 - loss: 0.7119 - sparse_categorical_accuracy: 0.4375
3/15 [=====>........................] - ETA: 9:17 - loss: 0.7036 - sparse_categorical_accuracy: 0.5208
4/15 [=======>......................] - ETA: 8:30 - loss: 0.7020 - sparse_categorical_accuracy: 0.5469
15/15 [==============================] - 914s 56s/step - loss: 0.6995 - sparse_categorical_accuracy: 0.5397 - val_loss: 0.6157 - val_sparse_categorical_accuracy: 0.7188
Our model provides an impressive accuracy of 71.88% on our holdout data.
I test-drive our model with the following quote:
"It's in the houses of spiteful old widows that one finds such cleanliness," Raskolnikov thought again, and he stole a curious glance at the cotton curtain over the door leading into another tiny room, in which stood the old woman's bed and chest of drawers and into which he had never looked before. These two rooms made up the whole flat.
I need to escape the quotes when I call the Model:
classifier.predict(["\"It's in the houses of spiteful old widows that one finds such cleanliness,\" Raskolnikov thought again, and he stole a curious glance at the cotton curtain over the door leading into another tiny room, in which stood the old woman's bed and chest of drawers and into which he had never looked before. These two rooms made up the whole flat."])
The model outputs disappointing results, with no clear prediction of class Raskolnikov.
1/1 [==============================] - 7s 7s/step
array([[-0.01614, -0.0249 ]], dtype=float16)
Label Crime and Punishment
I feed the entire text of Crime and Punishment into my model and have the model label each line.
First, I load the text into a Pandas Dataframe.
df = pd.read_csv('cp.csv', header=None, names=['Crime'])
df.head()
Crime
0 man came out of the garret in which he lodged ...
1 - "Good God!" he cried, "can it be, can it be,...
2 - "N-no," answered Dounia, with more animation...
3 - "What a pig you are!'
4 - nero - uf dis atari - 3 sae ; afeeyeeinae as...
The Dataframe includes 4,425 rows.
df.shape
(4425, 1)
I use a Lambda function to send each row of the text to my model. The model returns a prediction in the form of [[Likelihood of Other, Likelihood of Raskolnikov]].
lb = df.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
The prediction consumes three hours of clock time to complete.
In the end, I get a Series with predictions for each line of text.
lb.head()
0 [[-0.00489, -0.01569]]
1 [[0.2327, 0.1193]]
2 [[0.11, 0.04248]]
3 [[-0.06537, 0.1735]]
4 [[-0.1049, 0.359]]
I join the predictions Series with the Crime and Punishment Dataframe.
cp = df.merge(lb.to_frame(name='Result'), left_index=True, right_index=True)
This produces a Dataframe with the following structure.
cp.head()
Crime Result
0 man came out of the garret in which he lodged ... [[-0.00489, -0.01569]]
1 - "Good God!" he cried, "can it be, can it be,... [[0.2327, 0.1193]]
2 - "N-no," answered Dounia, with more animation... [[0.11, 0.04248]]
3 - "What a pig you are!' [[-0.06537, 0.1735]]
4 - nero - uf dis atari - 3 sae ; afeeyeeinae as... [[-0.1049, 0.359]]
Two Lambda functions extract the likelihoods from the Result array, and create two new Pandas columns.
cp['Other'] = cp.apply(lambda X: X['Result'][0][0], axis = 1 )
cp['Rask'] = cp.apply(lambda X: X['Result'][0][1], axis = 1 )
I create a Diff column to record the difference in likelihood between the two columns. Large differences indicate greater certainty.
cp['Diff'] = cp['Rask'] - cp['Other']
cp.head()
Crime Result Other Rask Diff
0 man came out of the garret in which he lodged ... [[-0.00489, -0.01569]] -0.004890 -0.015686 -0.010796
1 - "Good God!" he cried, "can it be, can it be,... [[0.2327, 0.1193]] 0.232666 0.119324 -0.113342
2 - "N-no," answered Dounia, with more animation... [[0.11, 0.04248]] 0.109985 0.042480 -0.067505
3 - "What a pig you are!' [[-0.06537, 0.1735]] -0.065369 0.173462 0.238770
4 - nero - uf dis atari - 3 sae ; afeeyeeinae as... [[-0.1049, 0.359]] -0.104919 0.358887 0.463867
You can find the full labeled text of Crime and Punishment here
A histogram illustrates the distribution of the likelihood differences:
cp['Diff'].hist(bins=20)
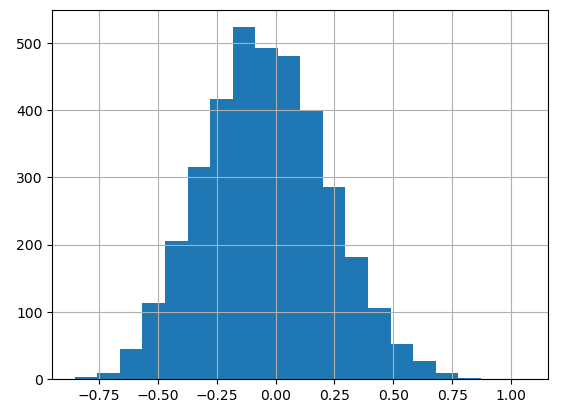
We need to set a threshold of certainty.
A threshold of 0.1 yields 1,088, a threshold of 0.2 yields 670 rows, and for both I see a few incorrect labels.
cp[cp['Diff'] > 0.1].apply(lambda X: print(X.Crime), axis=1)
""Ah, he's eating, then he's not ill," said Razumihin. He took a chair and sat down at the table opposite Raskolnikov.
"..» But I should like to know why mother has written to me about ‘our most rising generation'? Simply as a descriptive touch, or with the idea of prepossessing me in favour of Mr. Luzhin? Oh, the cunning of them! I should like to know one thing more: how far they were open with one another that day and night and all this time since? Was
"['ve only just waked up, and wanted to go to you, but was delayed owing tomy clothes; I forgot yesterday to ask
"A cup of tea, maybe."
"A notice from the office," he announced, as he gave him the paper.
"A painter?"
"A pickpocket I dare say."
"A priest," he articulated huskily.
"A strange scene passed between us last time we met, Rodion Romanovitch. Our first interview, too, was a
...
I set the threshold to 0.3 and save the Data Frame into a text file. This threshold still yields incorrect labels.
cp[cp['Diff'] > 0.3].apply(lambda X: print(X.Crime), axis=1)
"I am the murderer. . . . I want to give evidence," Nikolay pronounced,
"I am thinking," he answered seriously after a pause.
I beg you to say no more," said Raskolnikov. "In any case this is unpardonable impertinence."
"I can't help it... . 1 will come in half an hour. Tell them."
"I do,' repeated Raskolnikov, raising his eyes to Porfiry.
"I don't want it," said Raskolnikov, pushing away the pen.
"I fainted then because it was so close and the smell of paint," said Raskolnikov.
"I know."
"I remember now," said Raskolnikov after a long, suller silence. Razumihin looked at him, frowning and uneasy.
"I say nothing about him," added Raskolnikov, pointing to Razumihin, "though he has had nothing from me either but insult and trouble."
"I suppose you didn't expect it?" said Raskolnikov who, though he had not fully grasped the situation, had regained his courage.
"I was summoned... by a notice..." Raskolnikov faltered.
"I won't drink anything," said Raskolnikov.
rask_df = cp[cp['Diff'] > 0.3]['Crime']
rask_df.to_csv('rask.txt', index=False)
Sentiment and Emotional analysis
I take the file of Raskolnikov quotes and feed the quotes into the Google Cloud Natural Language API.
I import the required libraries and set FILENAME to rask.txt.
import pandas as pd
from google.cloud import language_v1
FILENAME = 'rask.txt'
The following code then records the sentiment and magnitude of each Raskolnikov quote into a Pandas Dataframe.
See my post on Unabomber vs. Thoreau for details.
sentiment_dict = []
# Instantiates a client
client = language_v1.LanguageServiceClient()
with open(FILENAME, encoding='utf-8') as f:
for line in f:
if line.strip():
try:
document = language_v1.Document(content=line.strip(), type_=language_v1.Document.Type.PLAIN_TEXT)
sentiment = client.analyze_sentiment(request={'document': document}).document_sentiment
sentiment_dict.append( { \
'score' : sentiment.score, \
'magnitude' : sentiment.magnitude, \
'text' : line.strip() } )
except:
sentiment_dict.append( { \
'score' : 0.0, \
'magnitude' : 0.0, \
'text' : 'ERROR: {}'.format(line.strip()) } )
sentiment_df = pd.DataFrame(sentiment_dict)
sentiment_df.to_csv('{}_sentiment.csv'.format(FILENAME.split('.')[0]),
index= False)
This produces the following Dataframe:
score magnitude text
0 -0.6 0.6 Crime
1 0.0 0.0 - nero - uf dis atari - 3 sae ; afeeyeeinae as...
2 -0.3 0.3 "!""? he bent over her once"
3 -0.1 0.3 """""Ah, he's eating, then he's not ill,"" sai...
4 0.0 1.3 """..» But I should like to know why mother h...
... ... ... ...
367 -0.6 1.2 two sharp and suspicious eyes stared at him ou...
368 -0.2 0.2 "very much struck by your face this moraine. 4...
369 0.1 0.2 "Ves. g4V come,"""
370 -0.1 0.3 Well and what then? What shall I do with the f...
371 0.0 0.0 wiee:?? 7
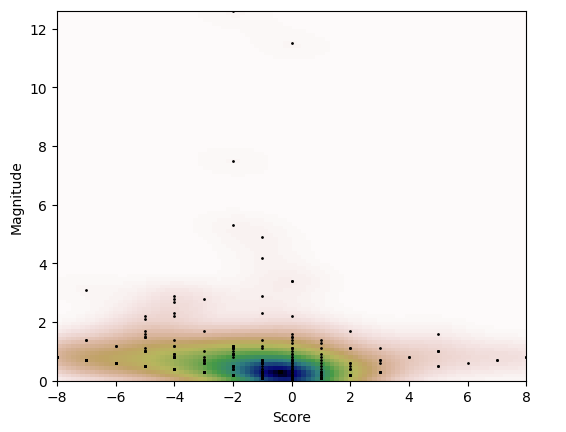
I use matplotlib to graph a Kernel Density Estimation Plot.
import numpy as np
from scipy import stats
m1 = sentiment_df['score']*10 #scaled to improve Data Viz
m2 = sentiment_df['magnitude']
xmin = m1.min()
xmax = m1.max()
ymin = m2.min()
ymax = m2.max()
X, Y = np.mgrid[xmin:xmax:100j, ymin:ymax:100j]
positions = np.vstack([X.ravel(), Y.ravel()])
values = np.vstack([m1, m2])
kernel = stats.gaussian_kde(values)
Z = np.reshape(kernel(positions).T, X.shape)
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.imshow(np.rot90(Z), cmap=plt.cm.gist_earth_r,
extent=[xmin, xmax, ymin, ymax])
ax.plot(m1, m2, 'k.', markersize=2)
ax.set_xlim([xmin, xmax])
ax.set_ylim([ymin, ymax])
plt.xlabel("Score")
plt.ylabel("Magnitude")
plt.show()
matplotlib produces the KDE plot.
Conclusion
I demonstrated how to use NLP to label speakers in a text. This allows Literary Analysts to apply NLP tools on a per-character vs. per-novel basis.
I first created a corpus of labeled training data. I then used transfer learning to customize a medium-scale BERT model to fit the training data. This produced a model that isolated Raskolnikov's quotes from Crime and Punishment
I use this approach in next month's post, where I compare Fyodor Dostoevsky's Rodion Raskolnikov (Crime and Punishment) with Ayn Rand's Howard Roark (The Fountainhead).
Coda
I ran into some issues with Keras and TensorFlow on Amazon Sagemaker. I record the issues and solutions here.
I received the ValueError: Unable to import backend : mxnet failure when I attempt to import keras-nlp.
Python 3.10.9 | packaged by conda-forge | (main, Feb 2 2023, 20:20:04) [GCC 11.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import keras_nlp
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/__init__.py", line 8, in <module>
from keras_nlp import layers
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/layers/__init__.py", line 8, in <module>
from keras_nlp.src.layers.modeling.cached_multi_head_attention import CachedMultiHeadAttention
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/src/__init__.py", line 23, in <module>
from keras_nlp.src import layers
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/src/layers/__init__.py", line 15, in <module>
from keras_nlp.src.layers.modeling.cached_multi_head_attention import (
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/src/layers/modeling/cached_multi_head_attention.py", line 16, in <module>
from keras_nlp.src.api_export import keras_nlp_export
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/src/api_export.py", line 17, in <module>
from keras_nlp.src.backend import keras
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/src/backend/__init__.py", line 27, in <module>
from keras_nlp.src.backend import config
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_nlp/src/backend/config.py", line 17, in <module>
import keras_core
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_core/__init__.py", line 8, in <module>
from keras_core import activations
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_core/activations/__init__.py", line 8, in <module>
from keras_core.src.activations import deserialize
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_core/src/__init__.py", line 1, in <module>
from keras_core.src import activations
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_core/src/activations/__init__.py", line 3, in <module>
from keras_core.src.activations.activations import elu
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_core/src/activations/activations.py", line 1, in <module>
from keras_core.src import backend
File "/home/ec2-user/anaconda3/lib/python3.10/site-packages/keras_core/src/backend/__init__.py", line 48, in <module>
raise ValueError(f"Unable to import backend : {backend()}")
ValueError: Unable to import backend : mxnet
>>>
The Keras-NLP team discovered that Amazon includes a hard-coded variable that calls MXNET upon launch of a new Sagemaker notebook.
!cat ~/.keras/keras.json
{
"floatx": "float32",
"epsilon": 1e-07,
"backend": "mxnet",
"image_data_format": "channels_first"
}
These commands fix the issue:
! echo { > out.txt
! echo ' "floatx": "float32",' >> out.txt
! echo ' "epsilon": 1e-07,' >> out.txt
! echo ' "backend": "tensorflow",' >> out.txt
! echo ' "image_data_format": "channels_first"' >> out.txt
! echo '}' >> out.txt
! cp out.txt ~/.keras/keras.json
I used the following library versions for this excursion.
keras==2.13.1
keras-core==0.1.2
keras-nlp==0.6.0
tensorflow==2.13.0
tensorflow-estimator==2.13.0
tensorflow-hub==0.14.0
tensorflow-io-gcs-filesystem==0.32.0
tensorflow-text==2.13.0
I also faced an issue where Sagemaker crashed when I labeled the entire book of Crime and Punishment. To solve the problem, I first split the text and then reassembled it after training.
df = pd.read_csv('cp.csv', header=None, names=['Crime'])
df1 = df[0:750]
df2 = df[751:1500]
df3 = df[1501:2250]
df4 = df[2251:3000]
df5 = df[3001:3750]
df6 = df[3751:]
lb1 = df1.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
lb1.to_csv('lb1.csv')
lb2 = df2.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
lb2.to_csv('lb2.csv')
lb3 = df3.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
lb3.to_csv('lb3.csv')
lb4 = df4.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
lb4.to_csv('lb4.csv')
lb5 = df5.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
lb5.to_csv('lb5.csv')
lb6 = df6.apply(lambda X: classifier.predict( [X['Crime']]), axis=1)
lb6.to_csv('lb6.csv')
df1z = df1.merge(lb1.to_frame(name='Result'), left_index=True, right_index=True)
df2z = df2.merge(lb2.to_frame(name='Result'), left_index=True, right_index=True)
df3z = df3.merge(lb3.to_frame(name='Result'), left_index=True, right_index=True)
df4z = df4.merge(lb4.to_frame(name='Result'), left_index=True, right_index=True)
df5z = df5.merge(lb5.to_frame(name='Result'), left_index=True, right_index=True)
df6z = df6.merge(lb6.to_frame(name='Result'), left_index=True, right_index=True)
cp = pd.concat([df1z, df2z, df3z, df4z, df5z, df6z])
Bibliography
- Dostoevsky, Fyodor. Crime and Punishment. Bantam Books, 1996.