I started my AI/ML journey in 2011 with a laptop model, a term which indicates a measure of size. Laptop models, by definition, do not exceed the compute, memory and storage resources of a single piece of hardware. The laptop model approach works well for small data sets, and modern hardware accommodates a few dozen GigaBytes (GB) of data with no issues.
The following cartoon demonstrates the laptop approach to model training and serving. (I use a brain icon to represent the ML model.)
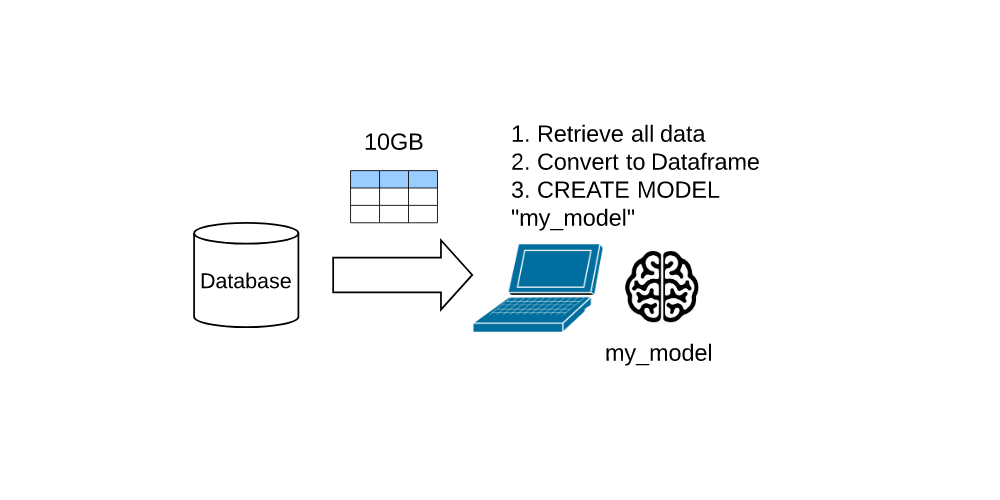
I still build, on occasion, laptop models when I have a small data set and I do not have access to the cloud. In general, however, I train models on Big Data, or data at PetaByte (PB) and higher scale. The laptop model approach, unfortunately, breaks down in the face of Big Data. Consider, for example, an attempt to train a ten (10) PB Dataset on a laptop.
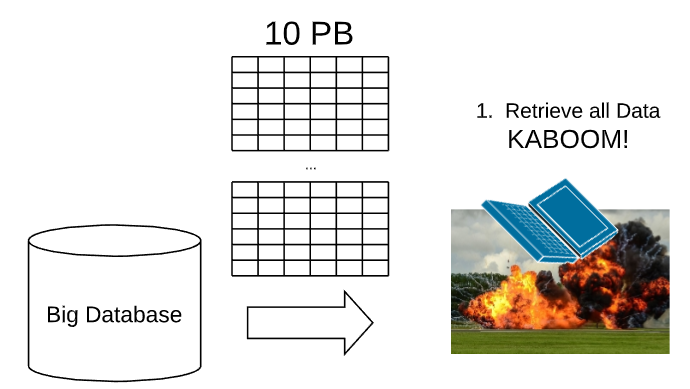
I do not know of a laptop that can accommodate 10 PB, and even if one existed, the compute and memory resources would not be able to train and serve at that scale. The cost and latency, furthermore, involved in transferring that amount of data across the Network also prohibits this approach.
Data Scientists, therefore, sample Big Datasets in order to work around the network, cost and resource constraints associated with Big Data driven laptop models. A sampled Dataset enables the Data Scientist to train and serve models on their laptops.
The following cartoon, for example, illustrates a Data Scientist who downloads one out of every one million (1M) rows at random. This reduces the data set from a cumbersome 10 PB to a manageable 10 GB.
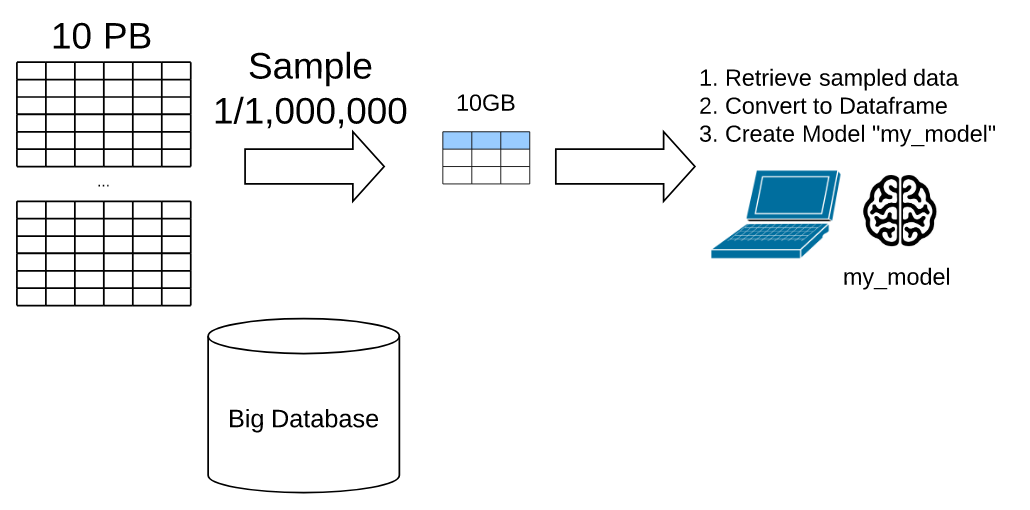
The sampling approach works from a technical standpoint. In order to accommodate resource constraints, however, the Data Scientist must throw away 99.9999% of the data. The ignored data may contain interesting outliers that could, for example, predict black swan events. So, from an information standpoint, the sampling approach lacks utility.
How can Data Scientists train and serve models on Big Data?
The issues with laptop models and sampling approaches result from the attempts of the Data Scientist to Bring the Data to the processing. A better approach, therefore, would be to bring the processing to the Data.
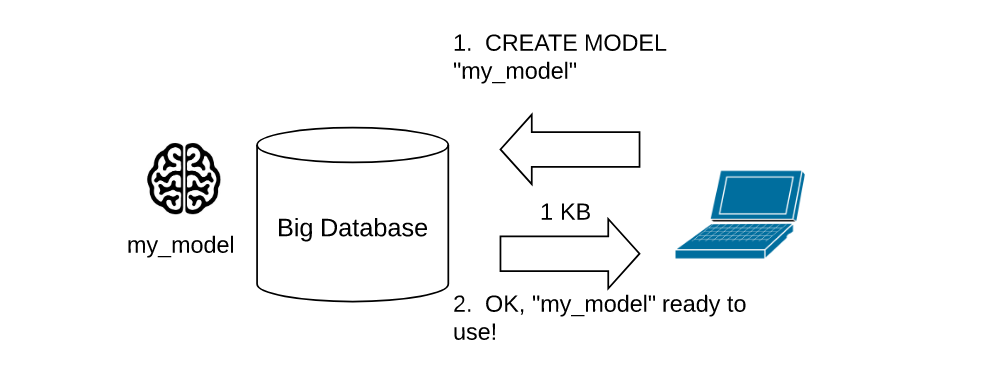
The Google Compute Platform (GCP) BigQuery service now enables Data Scientists to train models in place (or in-situ). They can train and serve models on their BigQuery Datasets without the need to move the data outside of Big Query.
The following Cartoon captures this phenomenon:
Test Drive BigQuery ML
We now will test drive the in-situ BigQuery ML and AutoML services, which allow us to train and serve data without the need to transfer the data out of BigQuery.
Add Data to BigQuery
If you have data in BigQuery, you can test drive BigQuery ML immediately. I will import the UC Davis Wine Quality Dataset into BigQuery.
I discussed the UC Davis Wine Quality Dataset in last month's discussion of GCP AutoML Tables. Please open that link in a new tab to read a description of the data, along with a discussion of the quality of the GCP AutoML generated models.
Last month, I uploaded the UC Davis Wine Quality Dataset to a Google Cloud Storage bucket. I will now import data from that bucket into BigQuery. If you have issues with importing the Wine Quality Dataset into BigQuery via a GCS Bucket, please see that blog post for reference.
The BigQuery console provides a list of pinned projects. Select your project from the list. Google named my project shining chain. Google will provide you with a different, randomly generated name.
Select Create Database.
Name the dataset wine_dataset.
The BigQuery console now lists wine_dataset under your project name.
Click wine_dataset and then the PLUS (+) sign on the upper right in order to add a table.
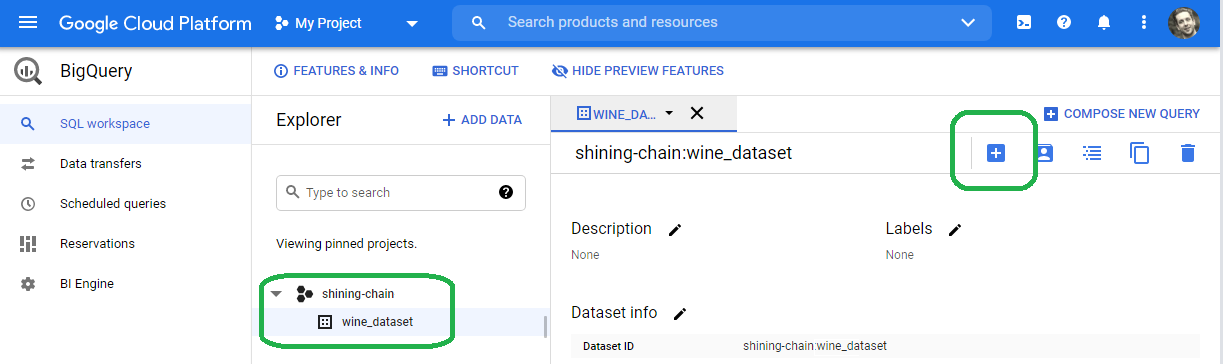
Select Create Table From Cloud Storage and then browse for your bucket.
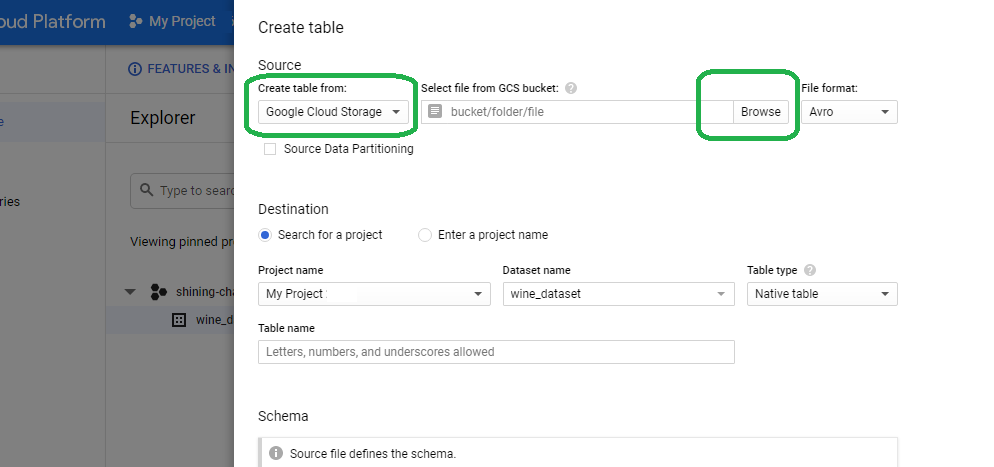
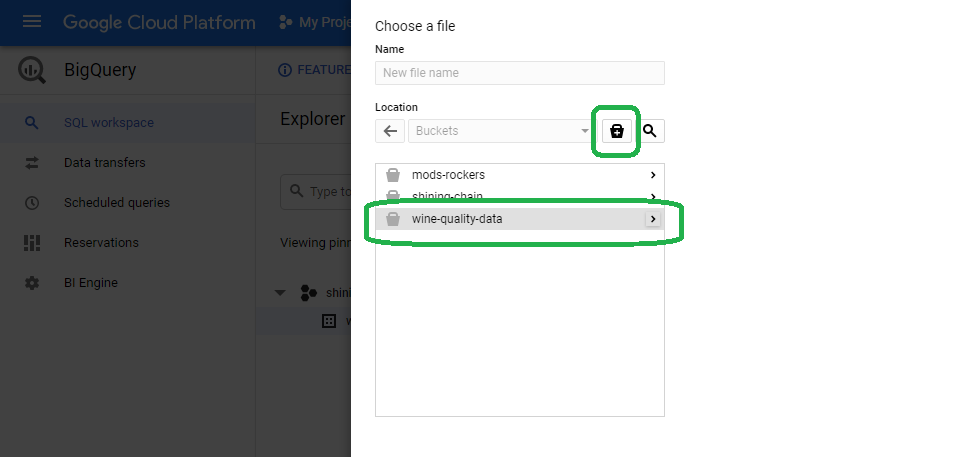
If you do not have a bucket with the wine quality dataset loaded, you can click the swiss lunch pail to create a new bucket now.
Add a table name (I named it wine_red), select auto-detect schema and save to close the wizard.
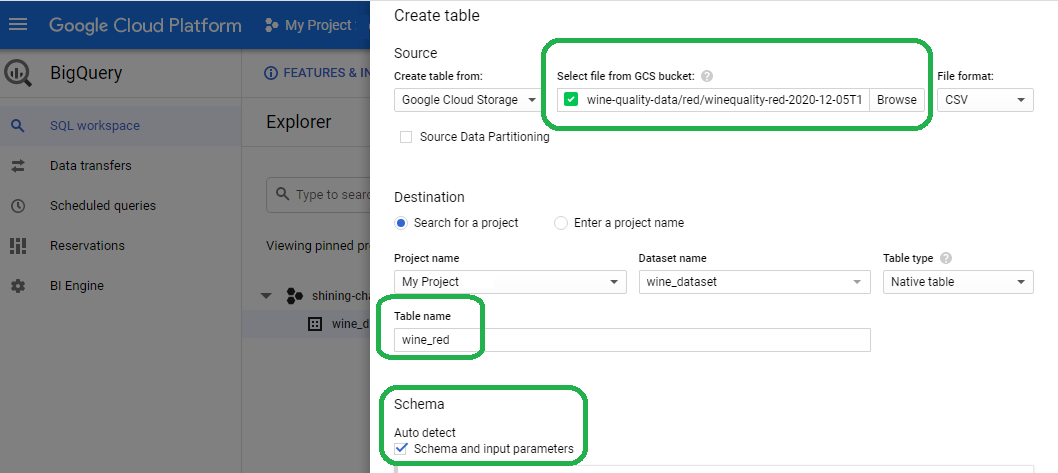
Auto-schema inferred FLOAT for all of our features, and INTEGER for our label.
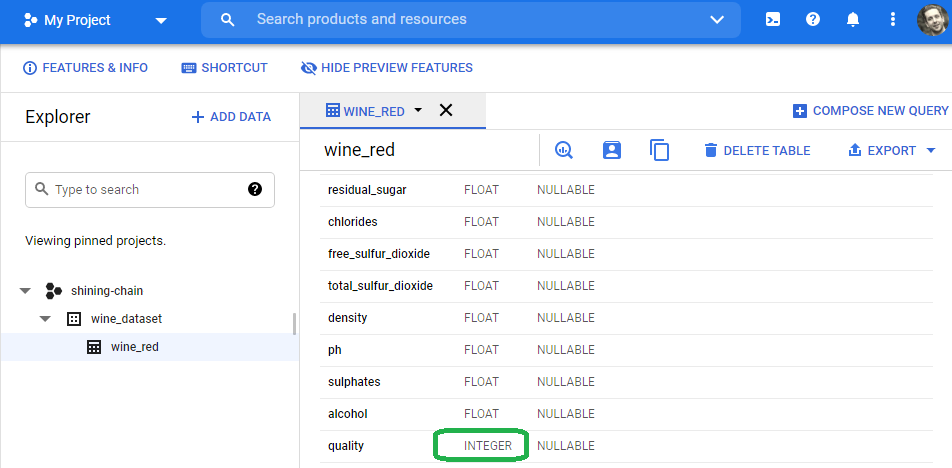
Select the wine_red table and then select preview to get a look at the data.
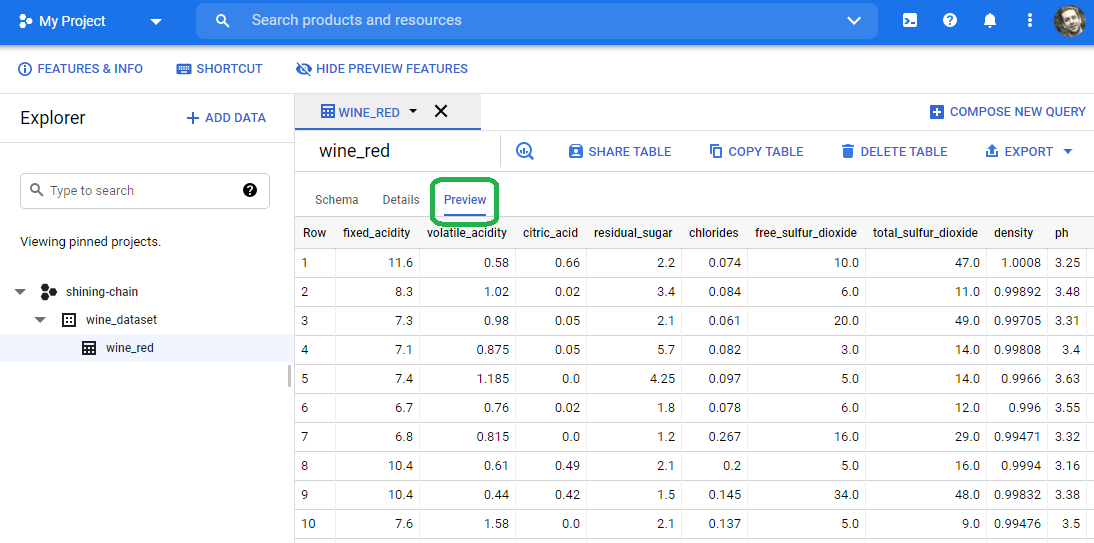
Linear Regression Model
We will now create our first model. To train a model in BigQuery we simply point BigQuery to a table, select the desired features and then indicate a LABEL feature, or target.
The wine quality dataset includes chemical markers and a rating from zero (0) to ten (10). Our wine model looks at the wine quality data to learn the relationship between these chemical markers and the quality. In other words, given a set of chemical markers, our model will predict the rating. For this reason, command BigQuery to use the quality feature for the target label.
Use SELECT AS syntax to indicate the target feature
BigQuery allows us to train a model via the CREATE MODEL SQL command. In the following SQL statement, I tell BigQuery to use the wine_red table, located in my wine_dataset Dataset, found in my shining_chain project. I also command SQL to create a model named model and place it in my wine_dataset Dataset, which lives in the shining_chain project. I use an SQL OPTIONS stanza to set the model_type to LINEAR_REG. Note that I include syntax that reads SELECT quality AS label FROM wine_red (I summarize it here). This instructs BigQuery to set the target feature to quality.
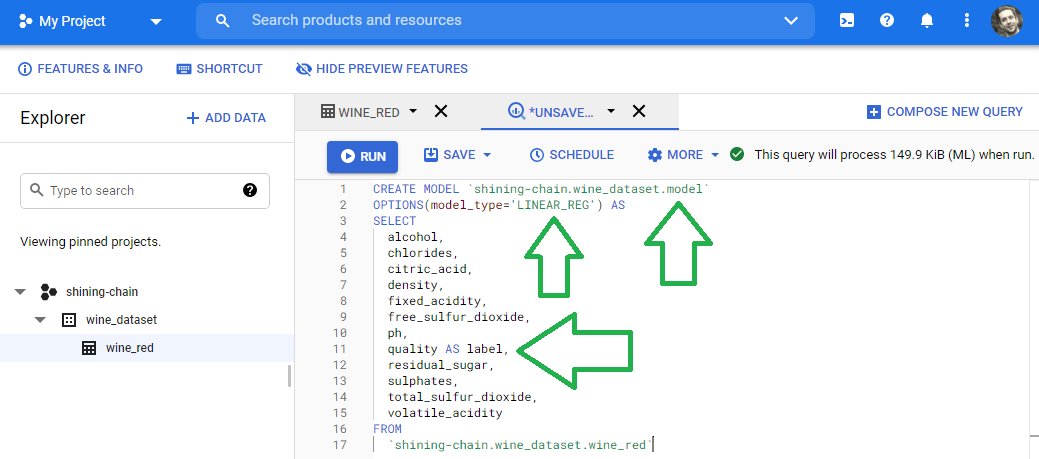
Read the SQL statement below to see the logic in action.
CREATE MODEL `shining-chain.wine_dataset.model`
OPTIONS(model_type='LINEAR_REG') AS
SELECT
alcohol,
chlorides,
citric_acid,
density,
fixed_acidity,
free_sulfur_dioxide,
ph,
quality AS label,
residual_sugar,
sulphates,
total_sulfur_dioxide,
volatile_acidity
FROM
`shining-chain.wine_dataset.model.wine_red`
Once the model completes the train stage, click on execution details. You will see that BigQuery used parallel processing to execute two (2) minutes worth of processing in fourteen (14) seconds.
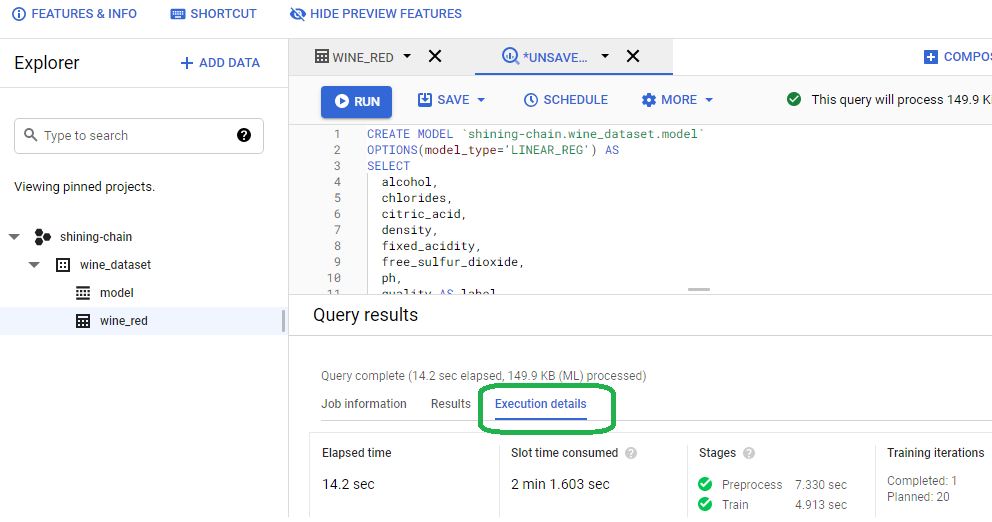
BigQuery also reports the model success metrics.
Click the Results tab and click Go to Model
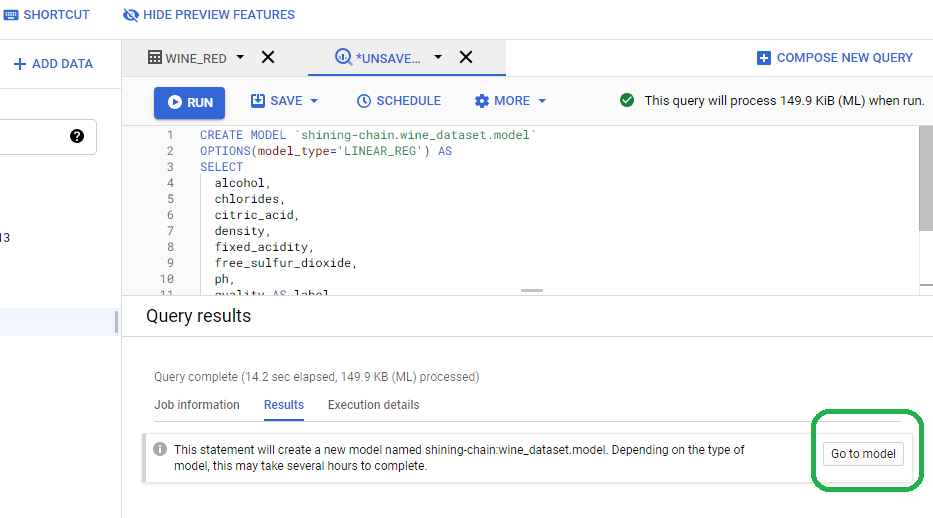
In accordance with (IAW) our SQL statement, BigQuery named our model model and stored it in the wine_dataset Dataset, which lives in the shining-chain project. Click model, click Evaluation and BigQuery will print the metrics.
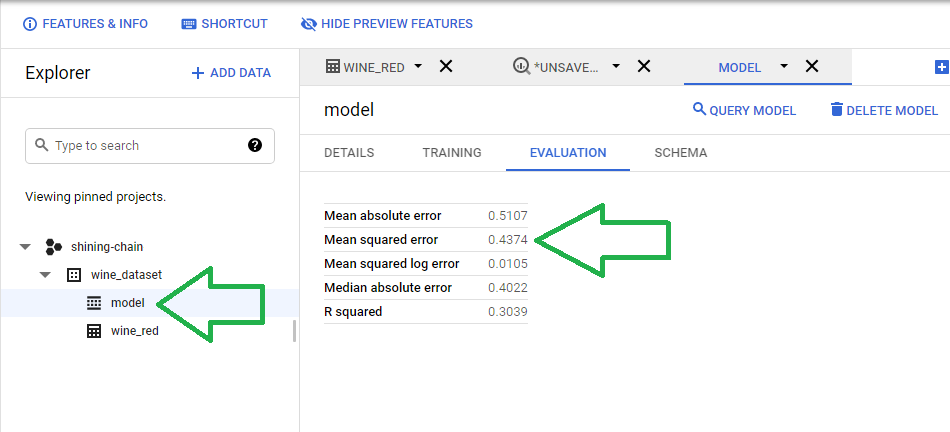
Our first model produces a MSE of 0.4374.
| Metric | Value |
|---|---|
| Mean absolute error | 0.5107 |
| Mean squared error | 0.4374 |
| Mean squared log error | 0.0105 |
| Median absolute error | 0.4022 |
| R squared | 0.3039 |
The MSE maps to a Root Mean Square Error (RMSE) of about 0.6614.
Last month, we tackled the Wine Quality Dataset with a variety of models and compared the results.
I capture the results table below:
| Rank | Approach | Dims | RMSE |
|---|---|---|---|
| 1 | AutoML Tables | 11 | 0.598 |
| 2 | Linear Model | 7 | 0.6327900 |
| 3 | DNN | 7 | 0.6449177 |
| 4 | DNN | 11 | 0.6483683 |
| 5 | BigQuery Linear | 11 | 0.6613622 |
| 6 | Linear Model | 11 | 0.7061977 |
| 7 | Linear Model | 2 | 0.7350416 |
| 8 | Guess Mean | N/A | 0.8012159 |
BigQuery's LINEAR_REG model out-performed the two Tensorflow models executed with default parameters. BiqQuery also beat the Guess Mean approach, which provides a good pace car for all of our investigations.
Note that a Linear Model applied to our feature reduced dataset landed in second place last month, which supports the claim that too many features leads to over-fitting and therefore lower performance.
Conclusion
Click the training tab and BQ provides training statistics.
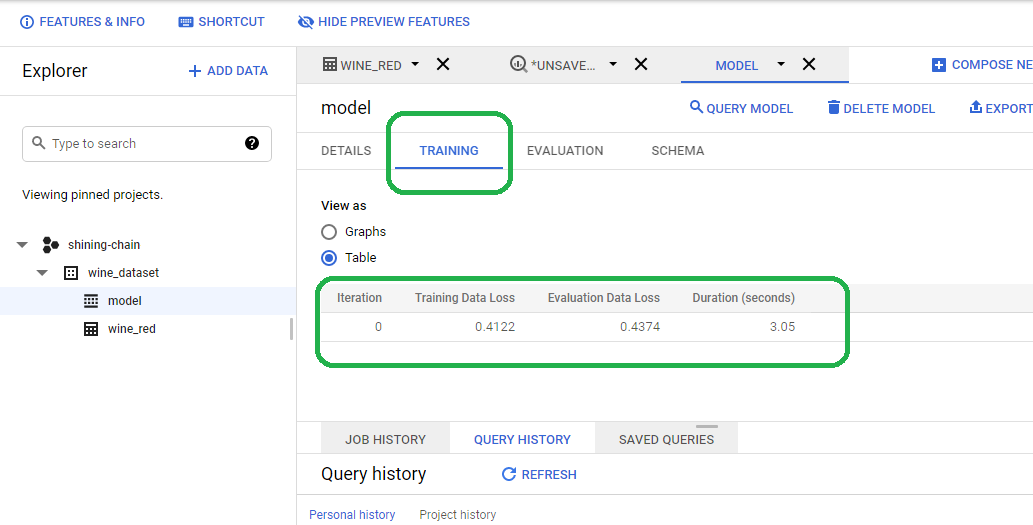
If you click details, you will see that BQ only created one model and stopped.
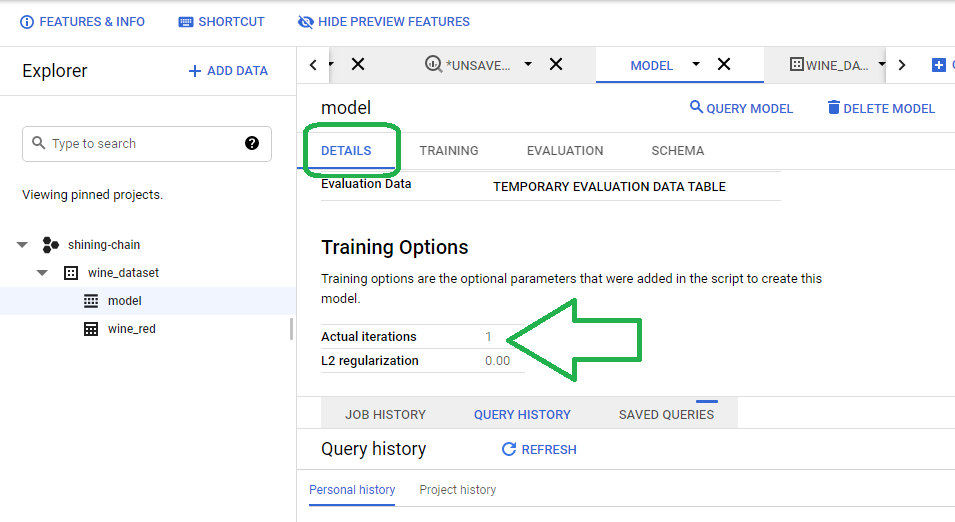
We commanded BigQuery to use the default configurations for learning rate, regularization and optimizer, create a model and stop there. We can increase the performance of our model, therefore, by tuning these Hyperparameters. Adam, for example, may perform better than Stochastic Gradient Descent. In general, Data Scientists will run through a variety of hyperparameter settings, iterate and then keep the best performing set of configuration options.
In the past, Data Scientists needed to tune these parameters by hand. The AI/ML industry, however, now provides a host of AutoML solutions, that execute model tuning without the need for operator involvement.
BigQuery, in fact, just unlocked a Beta service that allows us to execute AutoML in-situ.
We discuss In-Situ AutoML via BigQuery next month. See you then!