Introduction
Government Acquisition Teams (and Academics) request written responses to gauge writers' capacity for difficult work. Good writing requires effort. Writers must provide clear, focused, and valuable prose to Readers.
Writers must do the work for the reader, and remove ambiguity, falsehoods, filler content, and irrelevant bloviating.
Generative AI provides a cheat code for writing. Putative writers enter text into a prompt, and the AI produces mediocre, passable text in seconds. GenAI undermines the goals of writing assignments. In the face of instant prose development, Acquisition Teams can no longer infer Offerers' work ethic and ability through writing assignments.
Today I propose a simple rubric to detect the use of GenAI in writing. Graders and reviewers can then decide how to penalize Offerers who use GenAI. Where traditional writing demonstrated an ability to work hard, GenAI use reflects a willingness to take shortcuts.
Prior Art
Liang et al developed a method to identify the likelihood of Large Language model use in Academic white papers. Liang:
present[s] an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM) [Liang 1]
Early attempts at LLM detection looked at individual articles. Liang's novel approach attempts detection based on the analysis of a large corpus.
We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. [Liang 1]
Their results
suggest that between 6.5% and 16.9% of text submitted as peer reviews to [Academic] conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates [Liang 1]
Consider that for a moment. Academic journals and conferences represent the pinnacle of creative and scientific thought. Submission requires a PhD or PhD track. Liang, however, discovered that nearly one in five submissions substantially used LLM to generate prose.
Liang correlates LLM use with low quality, procrastination, and apathy:
the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. [Liang 1]
The Rubric
Find my rubric below. Subtract one point (from 100) for each transgression. I explain my rationale in detail in the following sections.
| Category | Example |
|---|---|
| Meme Adjectives | meticulous, intricate, transformative |
| Empty Phrases | In today's digital landscape |
| Unsubstantiated Grandiosity | is crucial, is critical, is of paramount importance |
| Cliches | Acme Corp. is pleased to present |
| Adverbs | to share and decipher data seamlessly is paramount |
| Passive Voice/ Ambiguous Subject | OpenAI was founded in 2015 |
| The Verb To Be | OpenDaylight is a Software Defined Network (SDN) Controller. |
Take, for example, the following prose:
Acme Corp is pleased to present our new packet tech. In the intricate world of digital communication, the ability to label and prioritize data is paramount, especially when it comes to real-time data.
The above prose loses five points in two sentences. It includes a cliche, an empty phrase, two instances of passive voice, and an adverb.
Meme Adjectives
ChatGPT loves certain words. After the release of the public LLM, Liang discovered a 10x surge of certain words.
We find a significant shift in the frequency of certain tokens in ICLR 2024, with adjectives such as “commendable”, “meticulous”, and “intricate” showing 9.8, 34.7, and 11.2-fold increases in probability of occurring in a sentence. Liang 1
I took the following chart from Liang's paper, and give all credit to his team.
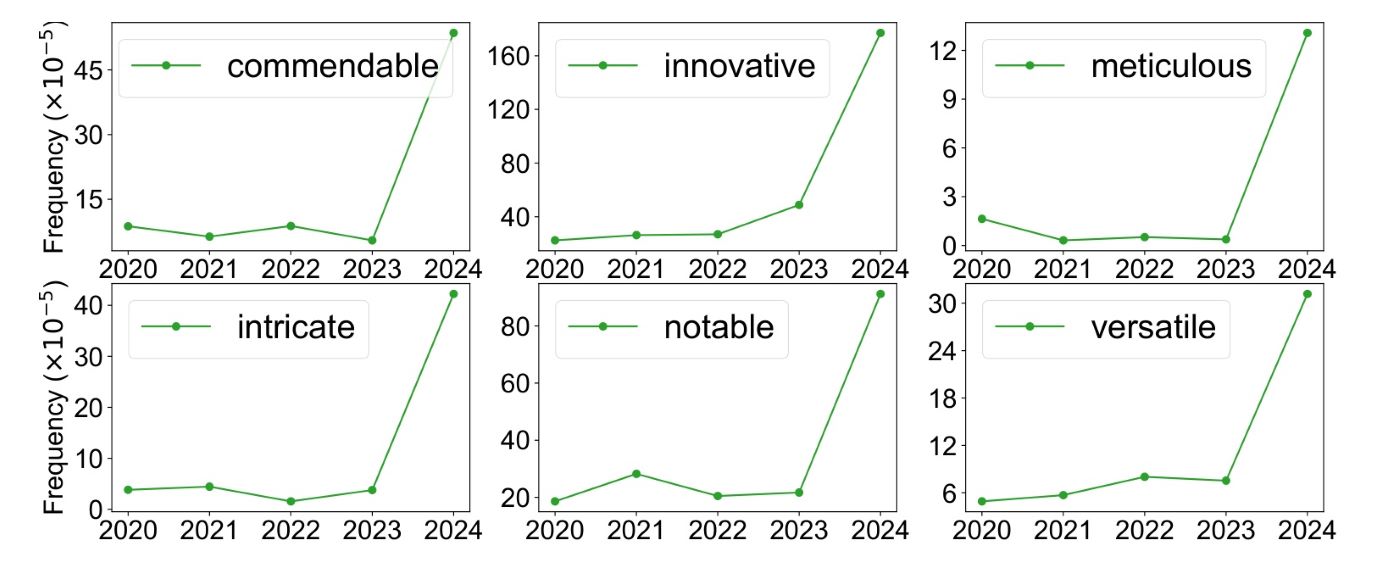
I consider the Meme adjectives meticulous, intricate and commendable unnecessary (attempts at) flourishes. They do not contribute to the information density of prose.
Page 15 of Monitoring AI-Modified Content at Scale provides a word cloud of Meme Adjectives. Again, credit to Liang and his team.
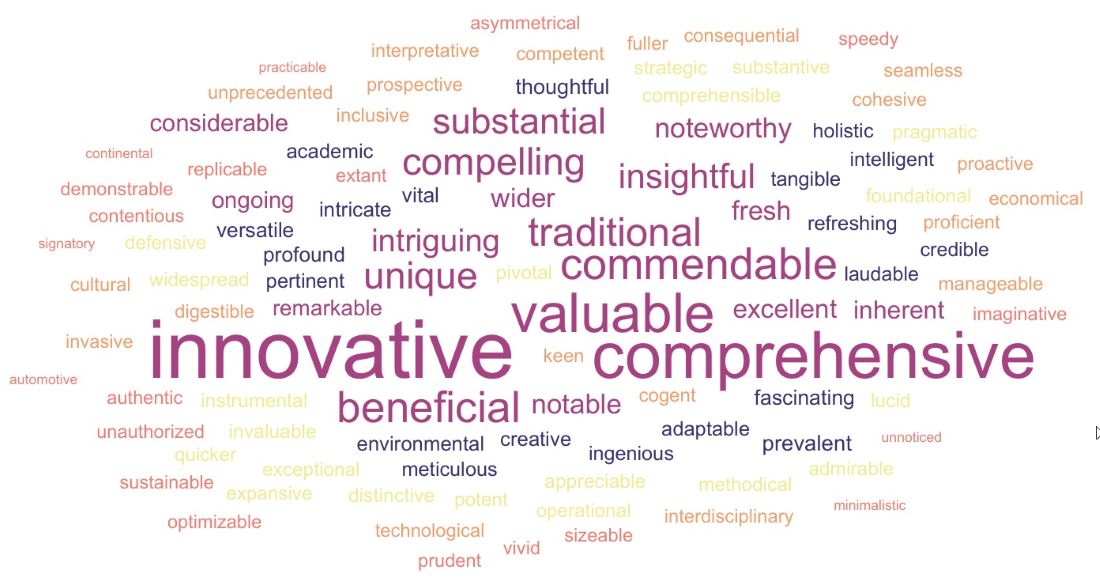
I propose we penalize authors that use these words.
Passive Voice/ Ambiguous Subject
In just a few months since I published my original thoughts on this subject, LLM improved their ability to remove passive voice. Simple prompt commands remove 80% of passive voice.
For example, consider the first reply from ChatGPT:
The OpenDaylight Project was founded in April 2013 and is hosted by the Linux Foundation. OpenDaylight is structured as a modular, pluggable, and flexible controller. It can be deployed on any hardware and operating system platform that supports Java. The platform is designed to separate...
The response includes myriad instances of passive voice. I ask ChatGPT to remove passive voice and it returns:
Founded in April 2013 and hosted by the Linux Foundation, OpenDaylight features a modular, pluggable, and flexible controller. This platform is deployable on any hardware and operating system platform supporting Java. OpenDaylight's design separates the control plane...
The response still includes passive voice. It identifies the founder but does not identify the designer. I ask it to
Rewrite the above to Subject-verb object form, removing all forms of to be and all passive voice.
It outputs:
The OpenDaylight Project, an open-source platform for Software-Defined Networking (SDN), accelerates SDN adoption and promotes... Founded in April 2013 and hosted by the Linux Foundation, OpenDaylight features a modular, pluggable, and flexible controller. This platform, deployable on any hardware and operating system platform supporting Java, separates...
I find this rule the most difficult to address. ChatGPT removes all forms of the verb to be from its response and removes passive voice. It still includes ambiguous subjects, for example, the reader will not know who would deploy the hardware.
This rule will only catch the most egregious of LLM use, and prompt engineers too lazy to ask the bot to refine the output.
Empty Phrases
ChatGPT peppers output with phrases that sound impressive at first read, but prove hollow and meaningless upon further inspection.
Take, for example, the phrase in today's digital landscape.
A Kagi Search (Non-affiliate link) of Digital Landscape returns myriad definitions. The domains of advertising, online games, and communications infrastructure policy all provide separate definitions.
ChatGPT should define digital landscape to remove ambiguity but I have not seen it do that prior its to use.
I collect several of these empty phrases in my Beat AI blog post. They include:
- In today's digital landscape
- In the intricate world of
- In this era of
- Unlocking new horizons
I recommend compiling a corpus of these phrases and then penalizing authors one point for each instance.
Cliches
Cliches add no information, just noise to text. Cliches offend the Readers' intelligence and demonstrate a Writer's lack of respect for their Reader's time.
- Tackle tough problems
- Best of breed
- Hit the ground running
- Low-hanging fruit
- Long pole in the tent
Unsubstantiated Grandiosity
Unsubstantiated Grandiosity prioritizes showy prose over the conveyance of useful information. Writers must convey useful information in tight, considerate prose. I've collected examples of LLM-produced Unsubstantiated Grandiosity in my prior blog post. Some include:
- Infrastructure as Code (IaC) is a paradigm-shifting approach
- Businesses can achieve unprecedented agility
- ...making them indispensable for decision-making
- Graphics Processing Units (GPUs) have transcended their original role...
- Digital advertising holds immense significance
An author must provide objective, well-cited, and appropriate evidence to build a case for a particular argument. They must do the work for their reader. Only after presenting substantial evidence can a writer tout a technology's importance.
Unsubstantiated Grandiosity provides a shortcut for lazy writers and attempts (and fails) to replace diligent research and evidence. It puts a cognitive load on the reader.
Adverbs
I put Adverbs in the category of lazy shortcuts. Thorough research and clear communication of relevant facts obviates the need for adverbs. For example:
- an increasingly important part of our global economy
- Embracing and diligently implementing security frameworks
- We seamlessly integrate different data sources
Require, for example, your authors to describe the processes and experience that would indicate seamless integration. Without proof, the adverb seamlessly rings hollow and subjective.
Conclusion
My Rubric provides a first-pass filter to penalize LLM use in Government Acquisition and Academic writing. It will only catch the laziest of writers. If AI companies can continue to follow observed trendlines, they will improve the proportion of relevant, objective, and fact-based content in LLM output.

In my last blog post, I recommend that readers demand prose in the form of subject verb object. I also recommend the removal of all forms of the verb to be. See that post for justification and examples. Since then, LLM proved adept at accommodating this request.
I considered recommending that authors cite journals and Academic papers to foil LLM usage since earlier LLM failed at this task. In July 2024, however, Grok AI shows promise on this front.
I use the following prompt:
Write two sentences about how we can detect LLM-generated code. Cite specific authors and quotes from current Academic journals.
Grok replies:
According to the research by Wu et al. in their paper titled "LLMDet: A Third Party Large Language Models Generated Text Detection Tool," published in the 2023 Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), a text detection tool called LLMDet can distinguish between different large language models and human-generated text, providing a specific probability for each source [1]. This tool represents a significant advancement in the field of detecting AI-generated content.
Additionally, a paper titled "Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector" by Wu et al. published in 2024 on arXiv highlights the challenge of detecting synthetic code generated by Large Language Models (LLMs) and proposes a sampling-based watermarking method for identifying machine-generated text, addressing the growing concern over the misuse of LLM-generated code in both educational and industrial domains [3].
Grok did not Cite any direct quotes, so the prompt engineer must do some manual work to find a direct quote.
Grok did not provide the details of the source. A follow-on prompt, however, will acquire it.
For example:
Cite the second paper's source in MLS format for a bibliography
Outputs:
Wu, L., Wu, X., & Wu, Y. (2024). Uncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector. arXiv preprint arXiv:2402.01234.
I believe LLM will evolve past detection.
Bibliography
- Liang, P., Wu, L., Wu, X., & Wu, Y. (2024). Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024). Association for Computational Linguistics.